

Модуль доступа к базе данных (Cache)
Модуль организован для унифицированного доступа к данным ЭМК на примере базы данных (БД) Cache и стандартов доступа FHIR с возможностью реализации специализированных сервисов выгрузки и генерации данных на базе доступной выборки пациентов.
Модуль состоит из двух подмодулей:
первый — обеспечивает интерфейс доступа к БД Cache (реализован форме набора скриптов на языке Cache Object Script),
второй — реализует функционал доступа, унификации и возможность генерации данных на результатах выгрузки (реализован в форме скриптов на языке Python).
В качестве средства унификации выбран стандарт и соответствующие технологии FHIR, обеспечивающие возможность:
а) естественного расширения модуля новыми подмодулями доступа к сторонним БД в других форматах;
б) реализации экспорта и интеграции модуля с современными медицинскими информационными системами (МИС), СППР и др. информационными системами.
В качестве демонстрационного примера на базе реализованного модуля создан демонстрационный сервис генерации синтетических данных пациентов (рис. 1), позволяющий создавать выборки анонимизированных пациентов с заданным заболеванием/осложнениями. Данный сервис может быть использован в целях обучения (в рамках лабораторных, школ-практикумов, хакатонов), для идентификации моделей на данных, для верификации моделей и пр.
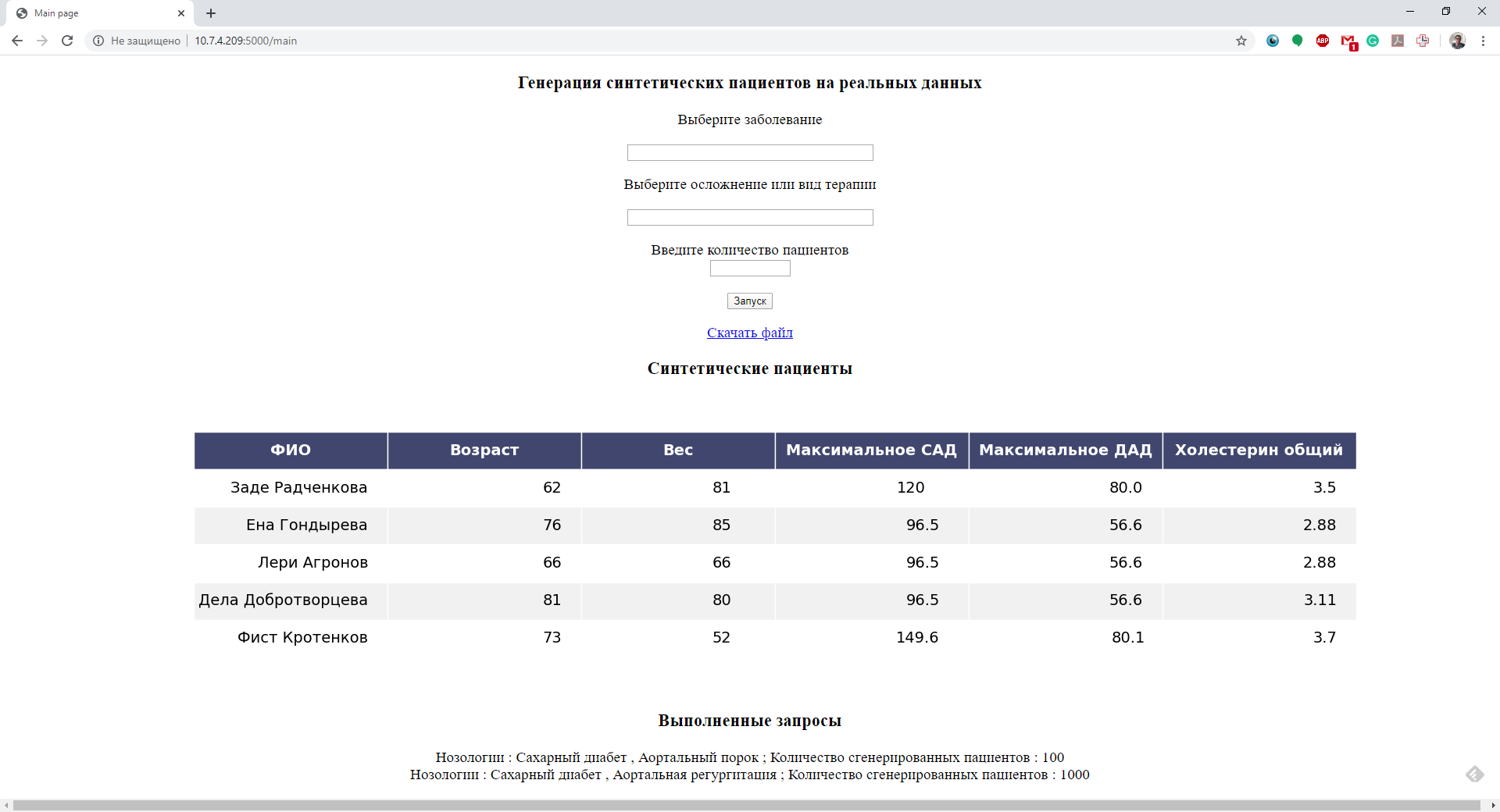
Рисунок 1 – Демонстрационный сервис генерации синтетических данных пациентов
Модуль представляет собой скрипт на языках Python, Cache Object Script и SQL.
На вход скрипту подается:
a) информация о способе хранения медицинских данных о пациенте: вид Базы Данных (БД), расположение БД, параметры доступа к БД;
б) База знаний, содержащая: схему хранения данных для конкретной базы, медицинские знания о существующих стандартах структурирования и хранения информации о пациенте.
Пользователь самостоятельно определяет какие данные и в каком виде ему нужны (FHIR, csv, json, цепочки событий, другое) с помощью реализованного интерфейса. Результатом работы программы являются извлеченные, структурированные и унифицированные данные согласно пользовательскому запросу и существующим реализованным в программе стандартам структурирования информации. Программа может работать с различными стандартами хранения медицинских данных пациента из электронных медицинских карт и с различными БД путем реализации адаптеров, поддерживающих соответствующий интерфейс. На Рисунке 2 показана общая схема работы модуля.
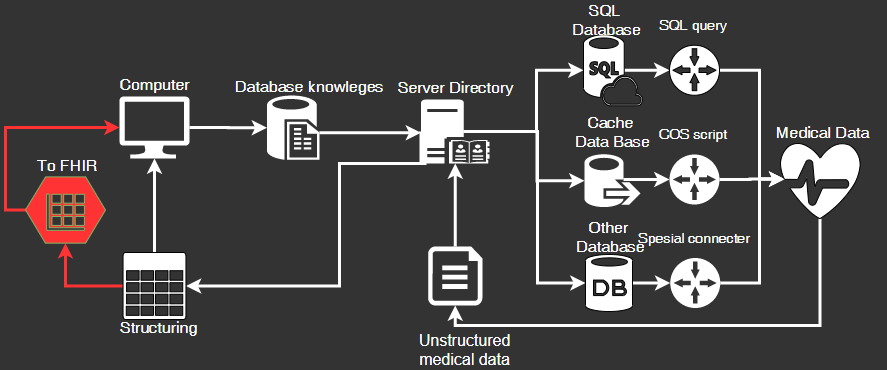
Рисунок 2 – Схема работы скрипта
Базу знаний можно обновлять согласно последним изменениям в мировых стандартах. Для использования разработки пользователю не нужны специальные знания в области IT, медицины, существующих стандартов медицинских данных пациента из электронных медицинских карт. Это является на наш взгляд главным преимуществом данного модуля.
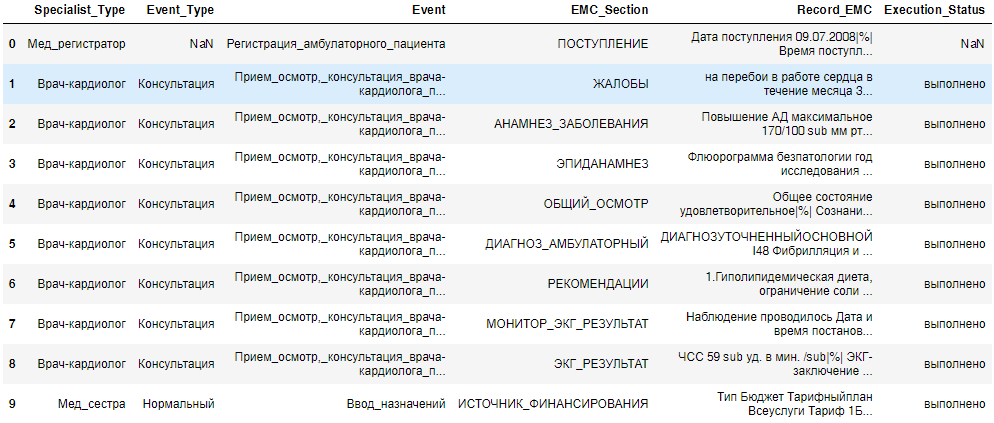
Рисунок 3 – Пример выгруженных ЭМК
На Рисунке 3 показан пример выгруженных и структурированных данные. Таблица содержит 10 колонок, из которых показано 5. Spesialist Type — специализация врача, который внес запись в базу, Event Type — тип приема (Консультация, Тест, Операция, и т.д.), EMC Section — раздел ЭМК, record EMC — запись врача на естественном языке и Execution Status — статус приема.
Email для обратной связи: ivderevitckii@itmo.ru