

Библиотека интерпретируемого интеллектуального
анализа процессов
Данная библиотека реализует возможности интеллектуального анализа процессов с высокой степенью неопределенности. Являясь эффективным инструментом для анализа бизнес-процессов по данным журнала событий (информации о прецедентах протекания анализируемых процессов), она обеспечивает автоматический контроль сложности, структурирование, выделение циклов, интеграцию с предсказательными моделями (в том числе моделями машинного обучения) и интерпретацию моделей процессов.
Библиотека реализует базовые алгоритмы интеллектуального анализа процессов (process mining, PM) с дополнительным функциональным расширением в части упрощения и интеллектуализации работы с формируемыми моделями. Она представляет собой набор скриптов на языке Python. В качестве базового функционала в библиотеке реализовано построение карт процессов по журналу событий с визуализацией на базе библиотеки graphviz.
Дополнительный оригинальный функционал включает в себя следующие возможности:
— Автоматическое выделение циклов с заданными параметрами детализации и формальным обоснованием целостности структуры.
— Автоматизированная настройка детализации при учёте вершин и рёбер в модели с использованием критериев оценки сложности и интерпретируемости формируемых графовых моделей.
— Возможность связи выделяемых циклов и событий с моделями машинного обучения (классификаторами) для интерпретации состояний в процессе моделирования (экспериментальный функционал).
Библиотека апробирована на задачах интеллектуального анализа процессов из медицины и здравоохранения: моделирование состояний и процессов лечения пациентов с хроническими заболеваниями, моделирование активности медицинского персонала и пр.
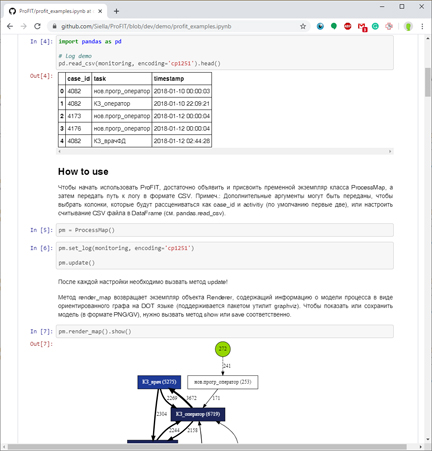
Рисунок 1 – Инструкция по применению библиотеки в формате Jupyter Notebook
В процессе использования библиотека принимает на вход журнал событий (лог), состоящий из нескольких случаев реализации процесса и записей о совершённых действиях (событиях), зарегистрированных в порядке их выполнения, и выдаёт графовое представление модели процесса (рис. 2), в которой связи между вершинами-событиями представлены в виде рёбер. Вершины в виде одинарного и двойного круга обозначают начало и конец процесса соответственно. Начальная вершина показывает общее количество случаев в журнале; на нетерминальных вершинах и рёбрах графа отображены абсолютные частоты событий и переходов соответственно.
Шаблон проектирования «Наблюдатель» реализован в основном классе ProcessMap, где «наблюдателями» являются объекты классов TransitionMatrix, Graph, Renderer, хранящие информацию о структуре процесса в формализованном виде. Единственный метод TransitionMatrix вычисляет вероятности появления событий и переходов, встретившихся в журнальных данных, путём построения вероятностной таблицы в виде вложенных словарей, которая затем используется для реализации алгоритма интеллектуального анализа процессов Fuzzy Miner. Основные идеи алгоритма по упрощению моделей процесса представлены в классе Graph. Класс Renderer хранит структуру процесса, которая может быть визуализирована посредством библиотеки Graphviz. Ниже описана более подробная схема работы библиотеки.
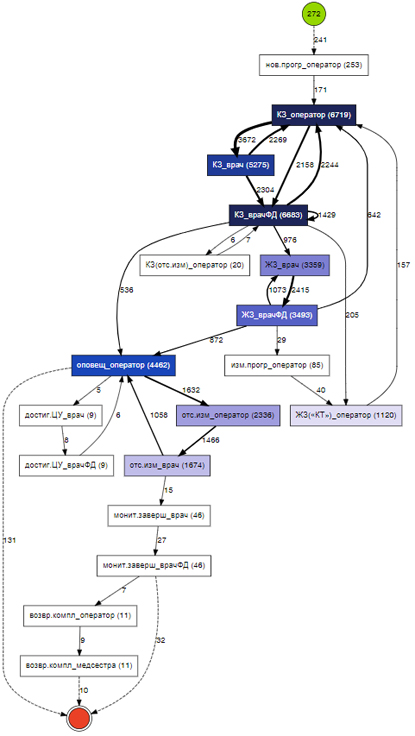
Рисунок 2 – Пример модели процесса, идентифицированной библиотекой по журнальным данным
дистанционного мониторинга пациентов с артериальной гипертензией
Для функционирования бибилиотеки достаточно передать на вход журнальные данные (путь к директории с лог-файлом), по которым строится вероятностная таблица, необходимая для упрощения модели процесса. На этапе фильтрации (упрощения) определяются наиболее вероятные события и переходы между ними в терминах Марковских дискретных случайных процессов, вычисляется их значимость в потоке событий. Пользователь может установить различные уровни отображения событий и переходов и тем самым регулировать полноту отображения процесса: если событие или переход превышает установленный порог, то оно отображается в модели процесса. Перед этапом фильтрации переходов происходит разрешение конфликтных ситуаций, когда два события в журнале могут следовать друг за другом в любом порядке и образуют цикл длины два. Это может означать как допустимое цикличное поведение в процессе, так и исключение, когда один из переходов – редкий частный случай, или же параллельность выполнения двух действий, когда в разных случаях исполнения процесса события совершаются в разном порядке. Для разрешения конфликтов в соответствии с их типами необходимо рассчитать относительную значимость конфликтующих переходов и обработать согласно установленному сценарию. В экземпляре класса Graph записываются полученные таким образом наборы вершин и рёбер графа, описывающего модель процесса в терминах нечётких сетей. Из-за особенностей нечётких сетей в модели процесса могут присутствовать мёртвые переходы, которые не связаны с началом или концом процесса, и даже компоненты связности. Чтобы избежать этого, реализованы два обхода графа в глубину, которые проверяют, является ли каждая вершина графа потомком стартовой и родителем конечной вершин процесса. Если это не так, то в каждом случае определяются компоненты графа, которые содержат вершины, удовлетворяющие и неудовлетворяющие условию соответственно, и добавляются дополнительные переходы в порядке их значимости, пока не будет получен связанный граф, отображающий исполнимый процесс. Если же не удалось найти такие переходы, то будут добавлены «мнимые» рёбра, связывающие начальную или конечную вершину процесса с выделенной компонентой графа.
Помимо изменения уровней отображений событий и переходов, пользователь может установить флаги для автоматизированной настройки детализации (не требует установки уровней отображения) и обобщения модели процесса. В первом случае решается задача оптимизации с целевой функцией, включающей термы потерь (несоответствие шага модели и шага лога) и сложности модели процесса как меры сложности графа: уровни отображений, доставляющие минимум целевой функции, будут использованы для построения модели процесса. Во втором случае реализован поиск циклов в графе и подсчёт их значимости путём воспроизведения лога: те циклы, чьи частоты появления в потоке событий превышают значение 0.5, будут интерпретированы как значимые, а вершины и рёбра, образующие такие циклы, агрегированы в мета-состояния (см. рис. 3). Такие состояния могут означать наиболее важные цикличные поведения в процессе, т.е. определённые его этапы, и могут быть интерпретированы как экспертом, так и с помощью моделей машинного обучения. Остальные параметры библиотеки регулируют спецификацию работы вышеописанных алгоритмов и не являются обязательными.
Библиотека была апробирована на задачах оптимизации информационных процессов в здравоохранении (снижение нагрузки на медицинский персонал, сокращение времени на получение услуги), а также как элемент СППР для врачей при построении общего сценария течения заболевания по заданной нозологии. Использование библиотеки не ограничивается данной областью применения, а только требованиями к входным данным и программному обеспечению, необходимому для функционирования программы. При этом используемые данные (журнал событий) могут быть доступны в рамках соответствующих предметных информационных систем или платформ обработки данных, сгенерированы с использованием имитационных моделей или сформированы в ходе работы аналитика-исследователя. Библиотека может применяться как в составе предметных приложений и сервисов по анализу различных процессов, так и в рамках расширения платформ аналитики больших данных и предсказательного моделирования.
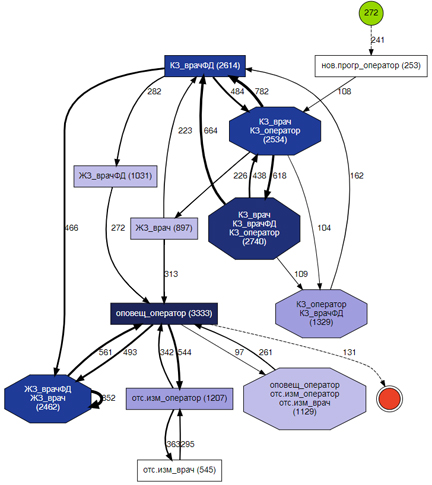
Рисунок 3 – Пример модели процесса, идентифицированной библиотекой по журнальным данным дистанционного мониторинга пациентов с артериальной гипертензией и агрегированной в мета-состояния
Email для обратной связи: lelkhovskaya@itmo.ru