

Библиотека анализа медицинских текстов
Библиотека решает насущную проблему отсутствия инструментария анализа и структурирования медицинских текстовыфх данных на русском языке, обеспечивает структурирование медицинских текстов (например текстов анамнезов, диагнозов, протоколов операций) с проверкой корректности (выявление опечаток), тематическим структурированием, выделением и формализацией специализированных структур (например, наследственного анамнеза).
Посредством библиотеки, в частности, повышается качество массового извлечения информации из текстовых данных (например, электронных медицинских карт) в виде категориальных и количественных переменных, необходимых для дальнейшего моделирования. Библиотека может применяться для анализа больших объемов неструктурированных медицинских текстовых данных в рамках задач анализа и предсказательного моделирования. Косвенно также решается проблема отсутствия размеченных корпусов медицинских текстов, необходимых для обучения и работы предсказательных моделей (библиотека формирует инструментарий для создания таких корпусов).
Библиотека представляет собой многофункциональную программную реализацию связанные функциональных модулей работы с медицинскими текстовыми данными: проверку корректности, выделение отрицаний в тексте, выделение тем (topic modelling), выделение сущностей по классам, выделение специализированных структур (например, наследственного анамнеза) и пр. Функционал библиотеки в настоящее время расширяется. Для интерактивной демонстрации возможностей библиотеки реализован сервис, позволяющий продемонстрировать функционал на примере трех избранных функций (рис. 1): выделение отрицаний, тематическая сегментация, поиск информации о родственниках в тексте.
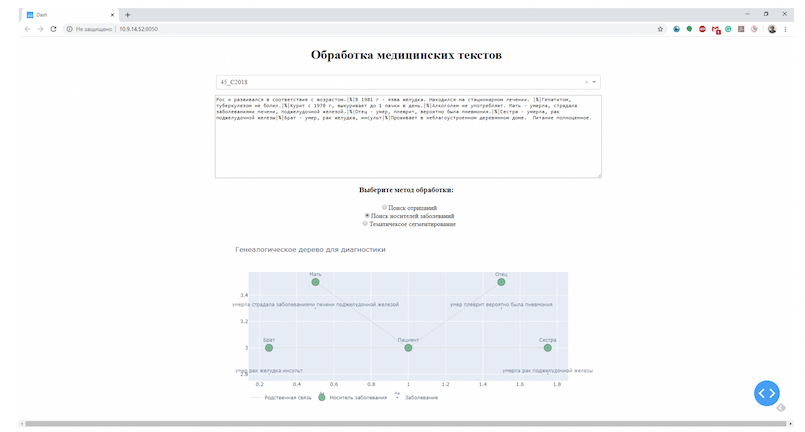
Рисунок 1 – Демонстратор возможностей библиотеки анализа медицинских текстов
Модуль автоматического исправления опечаток в медицинских текстах.
Модуль SpellChecker выполняет функцию исправления опечаток для нескольких типов ошибок: орфографические ошибки, пропущенные символы и опечатки, разделение слитно напечатанных слов, исправление сокращений.
Работа модуля состоит из двух основных этапов:
— Классификация слов на корректные и некорректные;
— Исправление некорректных слов.
Классификатор слов на корректный и некорректный тип работает на основе поиска слов в нормальной в форме в словарях русского языка и медицинской лексики, специфичной для исследуемого корпуса. Если слово есть в словаре – оно считается корректным и не участвует в дальнейшей обработке, в противном случае слово переходит на следующий этап.
Функционал исправления опечаток комбинирует в себе два основных метода. Первый подход - исправление ошибок с помощью поиска ближайших слов на основе расстояния Дамерау-Левенштейна. Данный подход работает эффективно при малом количестве символов в слове, написанных неверно. Второй подход - поиск ближайших слов на основе косинусного расстояния среди векторных представлений, полученных с помощью нейронной сети (FastText, skipgrams). Данный подход позволяет учесть контекст и семантику слов и отыскать слова схожие по смыслу. Оба подхода применяются последовательно. Сначала осуществляется поиск 10-ти ближайших слов по расстоянию Дамерау-Левешнтейна, затем из них выбирается слово близкое по смыслу на основе косинусного расстояния.
В текущей реализации в качестве результата пользователю возвращается исправленный текст со словами, приведенными в нормальную форму. Сейчас продолжается работа по уменьшению уровня ошибок работы модели по каждому типу некорректных написаний слов.
Модуль поиска отрицаний
Для обнаружения отрицаний или утверждений какого-либо диагноза в медицинских текстах строиться классификатор бустинга деревьев решений на корпусе размеченных текстов, так что каждый текст может иметь одну из следующих трёх меток: заболевание отрицается («-1»), заболевание в наличии («1»), заболевание не упоминается («0»). Тексты проходят стандартную обработку: лемматизация слов, удаление редких терм, TF-IDF преобразование мешка слов. В качестве эксперимента было построено пять классификаторов для поиска отрицания инсультов, инфаркта миокарда (ИМ), артериальной гипертензии (АГ), сахарного диабета (СД) и стенокардии. В среднем F-мера для каждого из классификаторов составляет от 0,81 до 0,93. Так как для поиска отрицаний используются тексты, а не только отдельные предложения, это позволяет учитывать контекст и выискивать дополнительные факторы, указывающие на наличие или отсутствия заболевания. Например, классификатор обнаружил, что при наличии стенокардии в прошлом пациент когда-то мог перенести операцию стентирования.
Модуль тематического моделирования
Тематические моделирования и сегментация предназначены для определения тем в наборе текстов и определения тем для каждого из предложений. Был разработан модуль для тематической сегментации на базе библиотеки BigARTM. В качестве эксперимента использовались анамнезы болезни пациентов с острым коронарным синдромом, для которых были обнаружены шесть тем: исследования, результаты ЭКГ и суточного мониторирования, рекомендации, стенокардия и её симптомы, хронические заболевания и информация о родственниках (рис. 2).
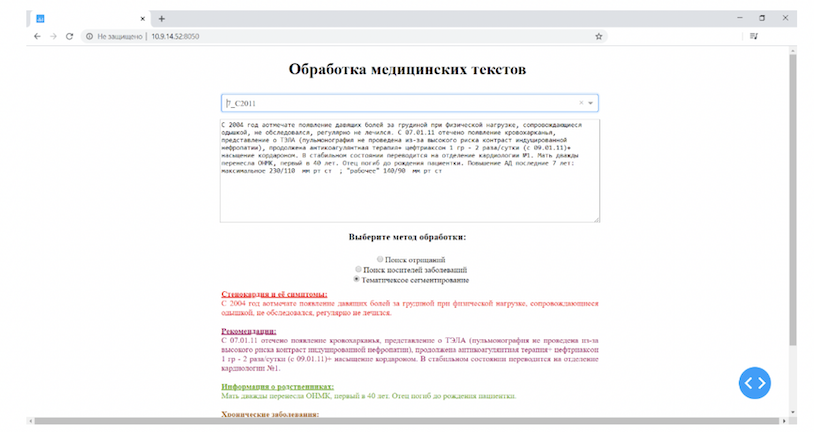
Рисунок 2 – Демонстратор возможностей модуля тематического моделирования
Модуль извлечения наследственных заболеваний
Модуль работы с наследственным анамнезом предназначен для фильтрации информации о пациенте и его родственниках, а также для дальнейшего анализа и моделирования наследственных заболеваний.
Работа модуля состоит из двух основных этапов:
— Бинарная классификация предложений по типу предложений о пациенте и предложений о родственниках
На первом этапе предложения приводятся в форму эмбеддингов с помощью метода Skip Grams (FastText). Затем происходит обучение модели градиентного бустинга над деревьями (xgboost) и предсказание класса предложения. Если предложение относится к типу «о родственниках», оно поступает на следующий этап обработки для определения класса родственника.
— Мульти-классификатор предложений по типу родственников.
На втором этапе предложения приводятся в форму векторного представления с помощью Count Vectorizer. Далее происходит обучение модели XGBoost и предсказание класса предложения. Затем запускается класс визуализации дерева семьи и потенциальных наследственных заболеваний. В качестве результата обработки запроса пользователя модуль возвращает визуализацию генеалогического дерева с наследственными заболеваниями.
ДОСТУП К БИБЛИОТЕКЕ
предоставляется по запросу
Email для обратной связи: k_balabaeva@itmo.ru, funkner.anastasia@itmo.ru