к.т.н., доцент факультета цифровых трансформаций, руководитель научно-исследовательских лабораторий «Когнитивные технологии в промышленности» и «Промышленный ИИ» в НЦКР Университета ИТМО
Денис Насонов 


Программа дополнительного профессионального образования
Курс предназначен для технических специалистов и технологических лидеров нижнего и среднего звена, имеющих представления и/или базовые навыки программирования для получения общих знаний о сквозной технологии «Большие данные» и начальных практических навыков в применении популярных программных средств в решении соответствующих практических задач.
Обучаемые не только прослушают лекции молодых, но уже имеющих ученую степень, практикующих преподавателей Университета ИТМО, но и своими руками на языке программирования Python разработают небольшие программы с применением технологий и систем Apache Spark, Apache Kafka, ClickHouse и др.
Программа рассчитана на широкий круг специалистов, имеющих представления и/или начальный опыт в алгоритмизации и программировании, которым необходимы базовые знания технологий больших данных и соответствующих программных средств, а также начальный опыт в последних:
— разработчикам/программистам начального и среднего уровня, в том числе начинающим дата-сайнтистам;
— системным администраторам, настраивающим и обслуживающим ИТ-инфраструктуры и оборудование конечного пользователя;
— предметным специалистам, которым необходимо применять технологии больших данных для решения задач, возникающих по роду их основной деятельности.
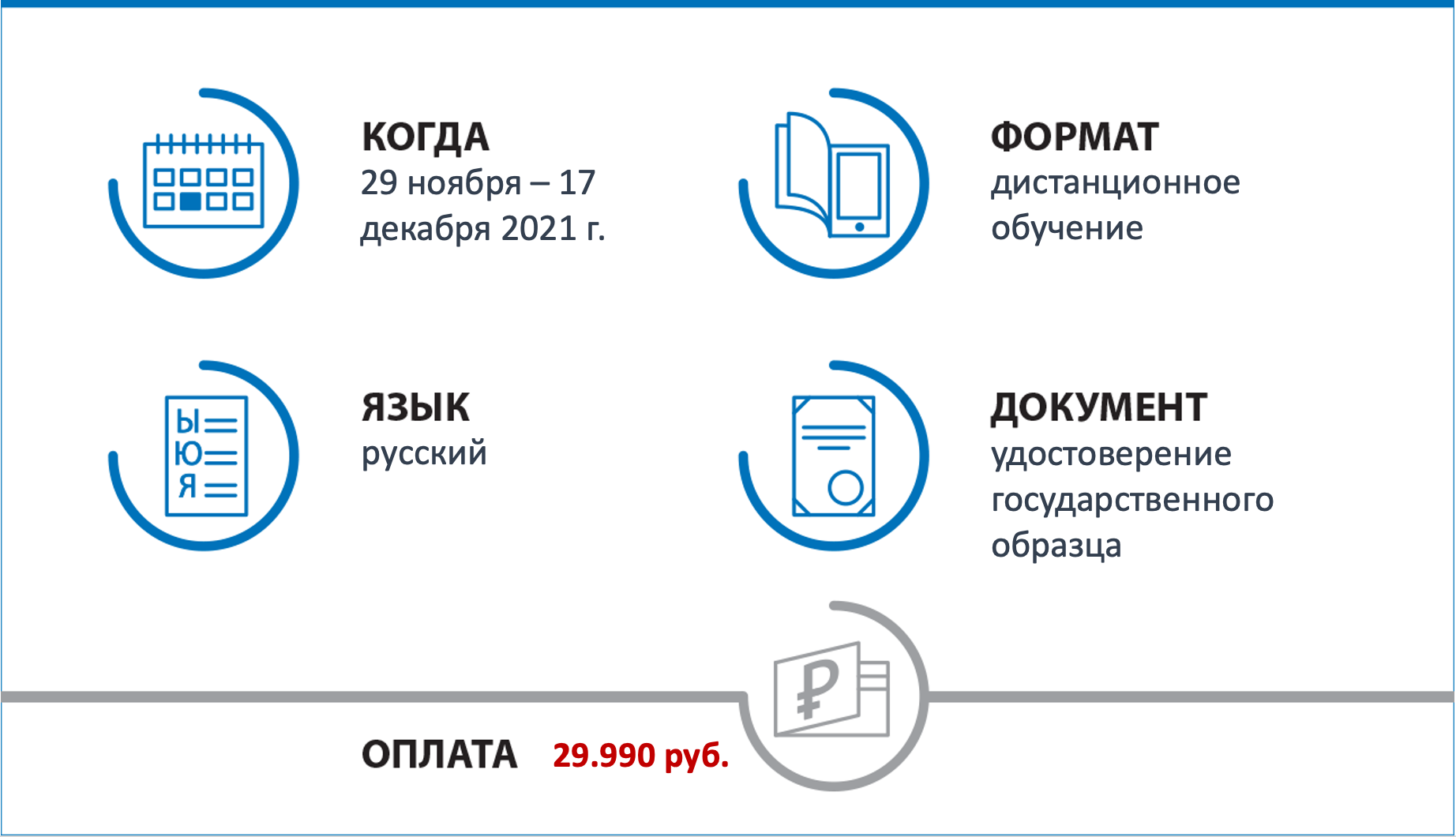
В рамках обучения слушатели:
— получат представления о технологиях больших данных и основных программных библиотеках для их реализации;
— научатся разрабатывать алгоритмы обработки и анализа больших данных в соответствии с поставленной задачей;
— получать начальный опыт в разработке программных средств начального уровня с применением стандартных библиотек больших данных.


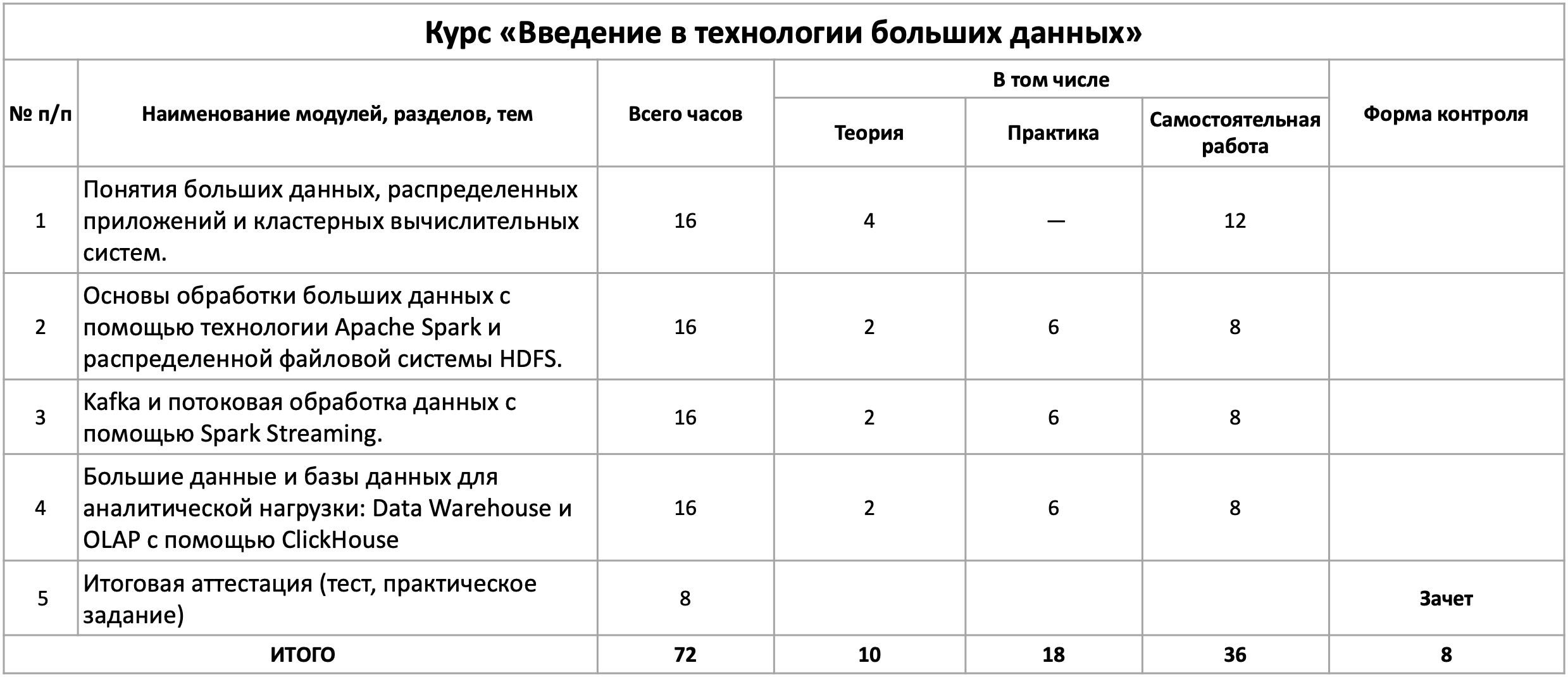
Тема 1
Понятия больших данных, распределенных приложений и кластерных вычислительных систем
В данной теме вводятся основные понятия из области обработки больших данных. Приводятся примеры практических приложений из реального мира и реальной практики, где применение технологий больших данных дает положительный эффект. Рассказывается о принципах устройства вычислительных кластеров и особенностях работы с ними. Также слушатели кратко знакомятся с функциями и назначением систем контейнеризации Docker и менеджера ресурсов кластера Kubernetes – наиболее распространенными для своих задач на текущей момент.
Тема 2
Основы обработки больших данных с помощью технологии Apache Spark и распределенной файловой системы HDFS
В данной теме рассказывается об основах обработки больших данных с помощью Apache Spark, их хранения на основе HDFS и доступа к ним. Рассматривается концепция MapReduce, а также ее развитие в SQL подобные операций для работы с несколькими большими датасетами. Знакомство с принципами обработки иллюстрируется с помощью небольших программ на языке Python и фреймворка Spark SQL. Кроме того, слушатели касаются основ оптимизации распределенной обработки и поиска «узких» мест.
Тема 3
Kafka и потоковая обработка данных с помощью Spark Streaming
В данной теме вводится другой подход к обработке больших данных - потоковый. Вводятся понятия throughput (пропускная способность) и latency (задержка). Рассматриваются приложения для которых актуальна и эффективна именно потоковая модель вместо традиционной пакетной, а также особенности обработки, специфичные для такой модели. Рассказывается и иллюстрируется применение решений Apache Kafka в качестве системы хранения очередей-потоков данных и Spark Streaming в качестве фреймворка обработки.
Тема 4
Большие данные и базы данных для аналитической нагрузки: Data Warehouse и OLAP с помощью ClickHouse
В данной теме вводится несколько ключевых понятий и примеров из области аналитики на основе обработки больших данных, в т.ч. концепция OLAP. Рассматриваются особенности организации хранения данных в рамках баз данных вместо файлового хранения. Также рассматриваются особенности устройства аналитических баз данных на примере БД ClickHouse и детально разбирается построение Data Warehouse средствами этой БД.
По всем вопросам, касающимся данного курса, можно обращаться по электронной почте: nccr.edu@itmo.ru
Чтобы записаться на обучение, пожалуйста, заполните предложенную форму.